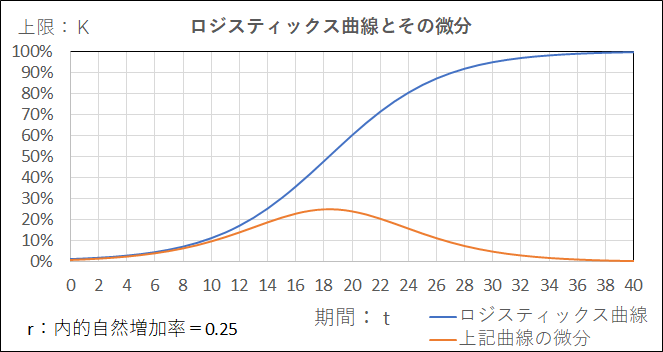
『施設園芸のPDCA』で紹介した(有)育葉産業様が高効率で高品質なミツバの生産の『生育予測』をエクセルで構築しているとの情報に接し、サブメニュー『生育予測モデルの方程式~AIへの展開』にて、ロジスティックス方程式で生育予測が出来るのではと思い検討した。
検討過程でロジスティックス曲線を更に『微分』する利用シーンとして、
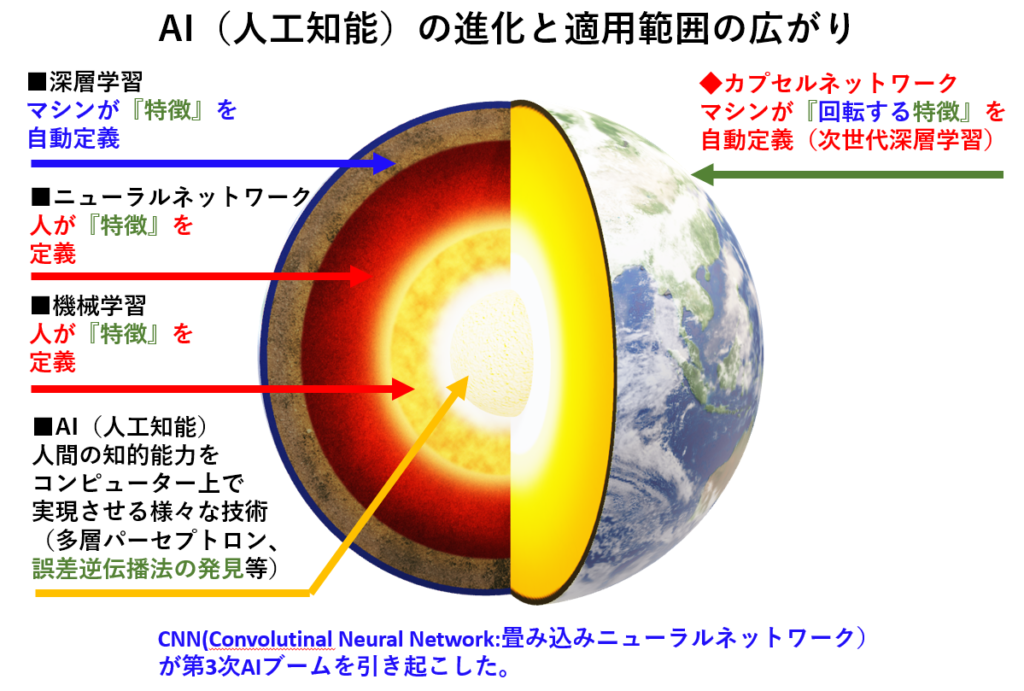
AI(深層学習)の活性化関数で有名なシグモイド関数( ロジスティックス曲線)の活用事例、
具体的には2値(クラス)分類の『誤差逆伝播』手法にて、出力層からの勾配計算(=誤差関数の重みに対する勾配)にシグモイド関数の微分が利用されている事に出会った。
当初とは全く予想外のAI(深層学習)への扉が目の前に現れ、思い切って扉を開いて、農産物生産プロセスの特定シーンにおいて AI(深層学習)活用ができないかとのテーマが新たに生まれた。
活性化関数を切り口にして、AI(深層学習)の活用を検討する当り、以下3ステップで検討を進める。
① AI(深層学習) の概要理解(準備編:今回のメニュ―内容)
② AI(深層学習) のコンセプト理解(個別メニュ―:DNNを学ぶ~Chat GPT-4事前学習~)
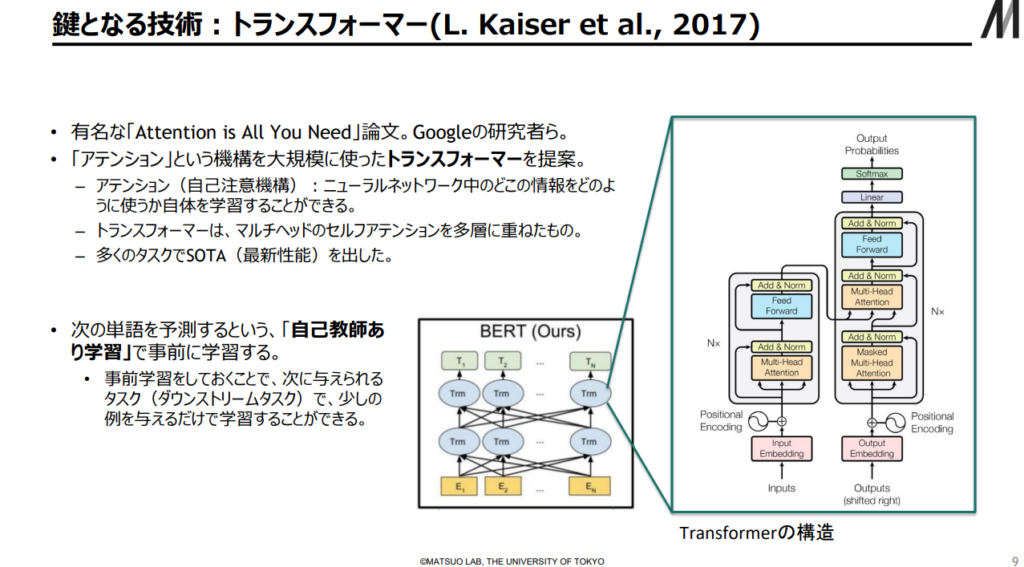
③生成AIの象徴であるChat GPT-4のフレームワークであるTransformer機構の理解
2023年3月中旬にBingに搭載された生成AIである『Chat GPT-4』が利用できるようになり、多様な分野のタスクにおいて、すでに人間に匹敵する働き(=アウトプット)ができており、出来栄え(アウトプット)の内容に大いに驚かされた。
一気に誰もが容易に実務で使えるようになったChat GPT-4の登場は、情報格差の壁(知識量の差による支配=専門家と非専門家の関係)を取り除き、ほぼ対等の立場で交渉ができるようになり、社会に大変革をもたらす事は容易に想像できるようになった。
Chat GPT-4のフレームワークであるTransformerの仕組みを良く理解し、今後の生成AIの動向及び社会に与える影響に関して判断できるようにする。
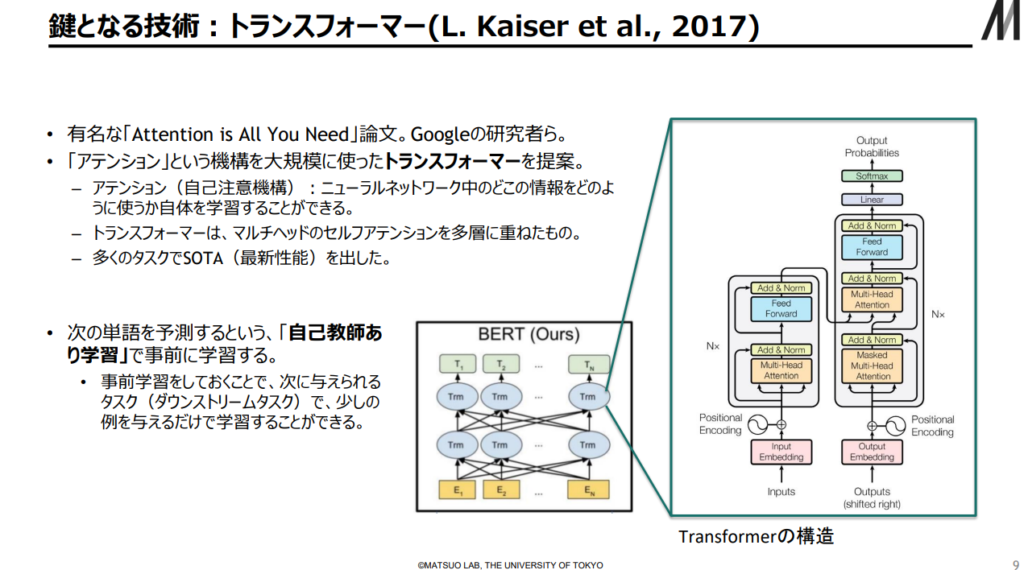
出典:AIの進化と日本の戦略 松尾研究室(23/2/17)

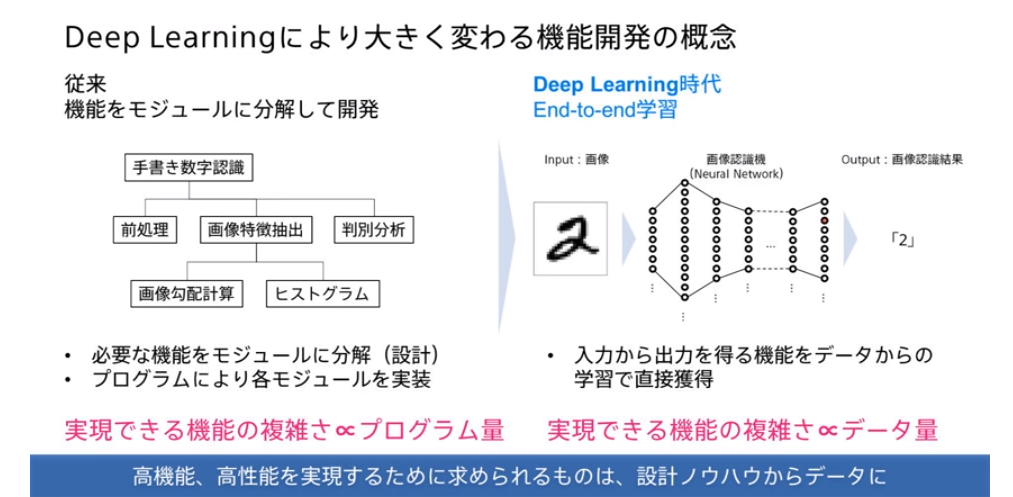
■■■Chat GPTにも適用されている『AI(深層学習)開発 手法』の特性■■■
従来型のソフトウェア開発の進め方とは根本的に違う事を前提に理解を進める。
下記2枚の図にてその違いを確認する。

国立研究開発法人 科学技術振興機構 研究開発センター

ソニーネットワークコミュニケーションズ(株)/ソニー(株)小林 由幸
■■AI(深層学習)=Deep Learning理解のゴールレベル:②AI(深層学習) のコンセプト理解■■
◆具体的なゴールレベル
・収穫したきゅうりの等級分け事例(農産物AI等級診断事例)
⇒等級ごとに275枚の写真を用意し、
⇒AI(深層学習)に学習をさせた事例がゴールレベルのイメージに近い。

・「きゅうりの学習済みモデル」に
⇒新しくきゅうりの画像を用意し、判定させた。
⇒すると正解率は80%。
その学習データを継続して使ううちに、95%まで正解率が上がったそうです。
(以上の記述の出典: 5分でわかる、Deep Learning(深層学習)の仕組み3つのポイント)
この AI(深層学習)活用(=未知のきゅうり画像から等級判断や予測を適正に行えるようになっていく)は農業の人手不足対策に利用されており、農業従事者の経験知をシステムが取り込む(=学習する)事で課題解決に一歩踏み込み、新たな価値を生み出している。
この等級情報がブロックチェーンのトランザクション情報(=生産履歴の出荷工程のトランザクション)に書き込まれる(=電子ファイルのハッシュ値が書き込まれる)シーンが容易に目に浮かぶ。これも品質保証の証拠データになる。
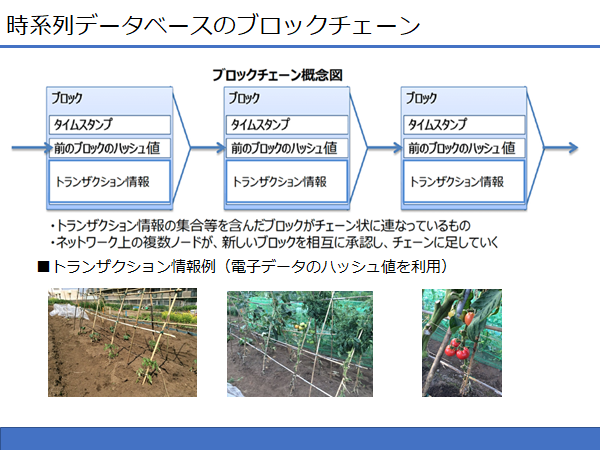
このようにAI(深層学習)も『特定の一つの問題を解かせるためのツール』 である事が分かる。
■今AI(深層学習=Deep Learning)に取り組む理由⇒農産物AI等級診断事例等の運用を目指して
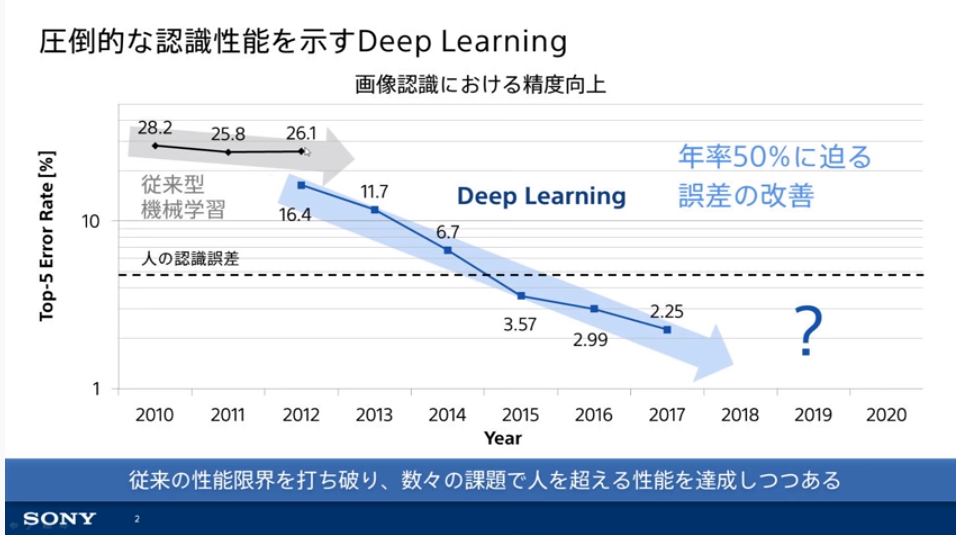
①圧倒的な認識性能を示す。
人間の認識精度を甘く評価した誤り率5.1%を既に超えている。 下図のトレンドラインで分かるように深層学習を取り組む価値が広く一般人にも認識されるようになってきている。
但し、人間の長年の経験による『直観』には到底及ばないが。
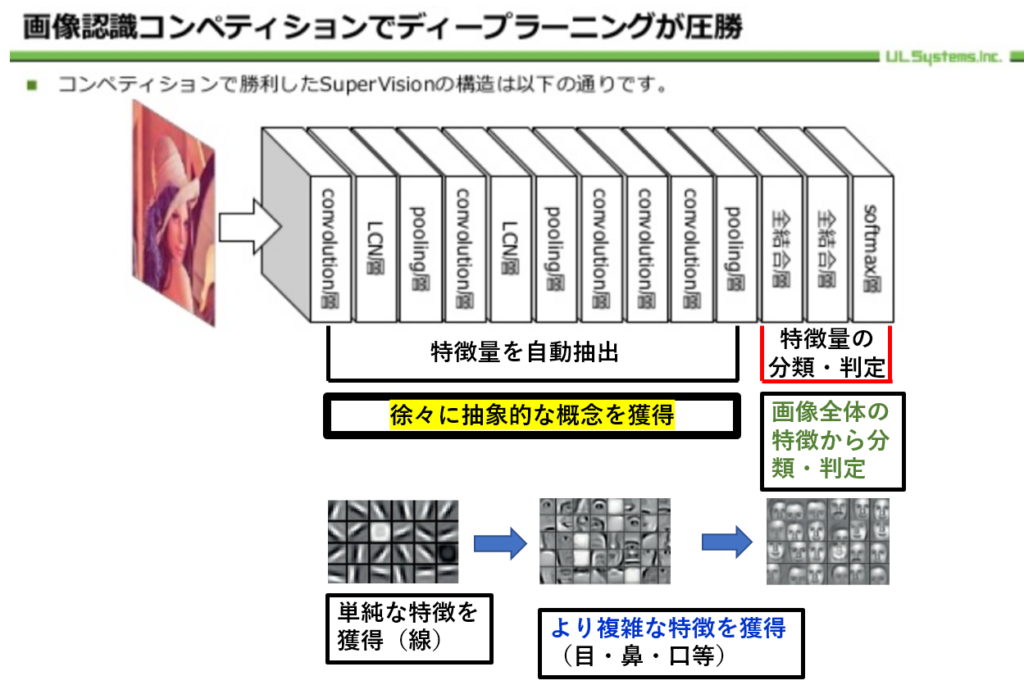
従来のAI(機械学習)による認識性能の限界を大きく突破させたのが、トロント大学のジェフリー・ヒントン教授らのグループによる、2012年の画像認識コンテスト「ILSVRC(ImageNet Large Scale Visual Recognition Challenge)」にて、ニューラルネットを用いたSupervisionという手法であった。
1年前の優勝記録の誤り率25.7%から15.3%へと4割も削減し圧勝し、第3次AIブームを引き起こしたと言われている。
ソニーネットワークコミュニケーションズ(株)/ソニー(株)小林 由幸
②大量のデータから『その特徴量を自動で抽出し学習する』といった機構(=仕組み)が有る。
深層学習以前の機会学習やニューラルネットの分野では 人手による『特徴量』の設計が必要であった。
人手で特徴量を設計するのはとても難しい。そのためこの分野では長い間,顕著な精度の向上が見られなかった。(下図にて具体例を紹介)
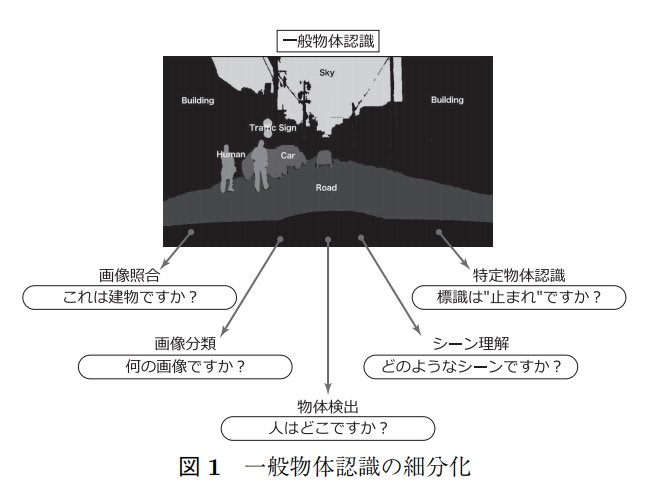
深層学習による画像認識
従来の機械学習(ここでは『深層学習』が注目される以前の手法と定義する)では、上図に示すように入力画像から直接一般物体認識を解くことは難しいため、この問題を画像照合・画像分類・物体検出・シーン理解・特定物体認識の各タスクに細分化して解いてきた。
人手の知見に基づいて設計したアルゴリズムにより特徴量を抽出・表現していたため、最適であるとは限らない。 (上記2行の出典先: 日本ロボット学会誌 Vol 35 No.3 pp.180~185 2017より)
ソニーネットワークコミュニケーションズ(株)/ソニー(株)小林 由幸
一方、深層学習は大量のデータから『その特徴量を自動で抽出し学習する』といった機構を持つ。
ヒントン教授らのSupervisionでは入力画像には最低限の前処理のみを行い、各ピクセルの画素値をそのままニューラルネットに与えていた。
・人手が必要と思われた特徴抽出を『自動化』し、
・その上で認識精度を向上させたディープラーニング(=深層学習)の登場は
⇒従来の手法を覆す大事件であり、ブレークスルー(=障壁の突破)が起きたと評価されている。
尚、トロント大学のジェフリー・ヒントン教授らが用いたモデルは CNN(Convolutinal Neural Network:畳み込みニューラルネットワーク)である。 CNNの原型 (ネオコグニトロン)を1979年に発表したのは日本人の福島邦彦氏であった。
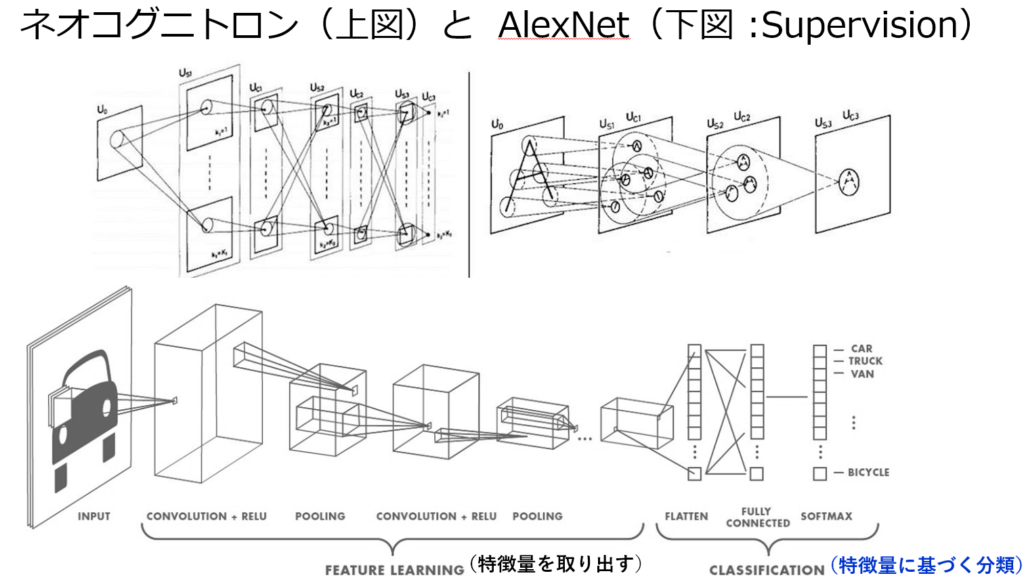
出典:下図: https://hackernoon.com/ What is a CapsNet or Capsule Network?
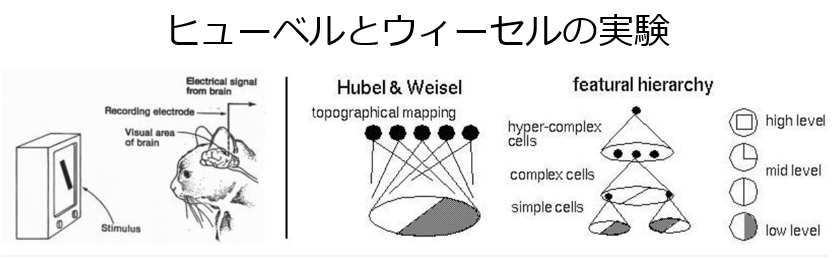
福島モデル( ネオコグニトロン )は、1960年代に動物の視覚野の特性を調べるため、神経生理学者のデイヴィッド・ヒューベルとトルステン・ウィーセルの実験知見にヒントを得て開発された経緯がある。 尚、両氏は1981年 ノーベル生理学・医学賞を受賞している。
・ネオコグニトロンは
⇒パターン認識においてある程度の成果を納め、
⇒畳み込みフィルターをニューラルネットワークに取り入れたものの、
⇒フィルター自体を学習するアルゴリズムを欠いていたために限界があった。
(出典: 畳み込みニューラルネットワークの記述)
・ヒューベルとウィーセルの実験より
⇒大脳皮質における感覚情報処理に関する知見が深まり、
⇒刺激提示位置や方位に対して選択的に応じるニューロン同士が規則的なルールに従って視覚野を形成していることなどを発見し、
⇒単純な刺激が複雑な像となって表れる視覚の仕組みを明らかにした。 (Wikipediaより)
畳み込みニューラルネットワーク
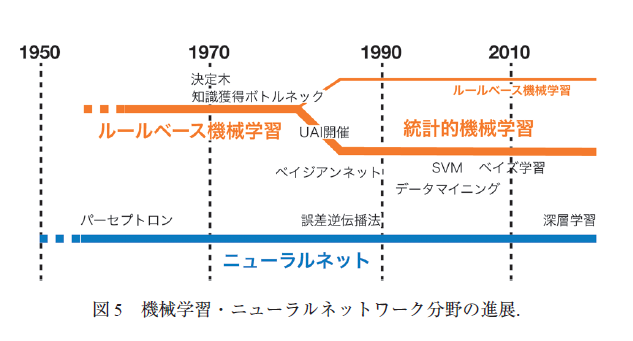
■■■AI歴史におけるブーム(第1次ブーム~第4次ブーム=生成AIの象徴としてのChat GPT-4)と冬の時代の経緯■■■
(シリーズ 人工知能と物理学 神嶌 敏弘 2019 日本物理学会)
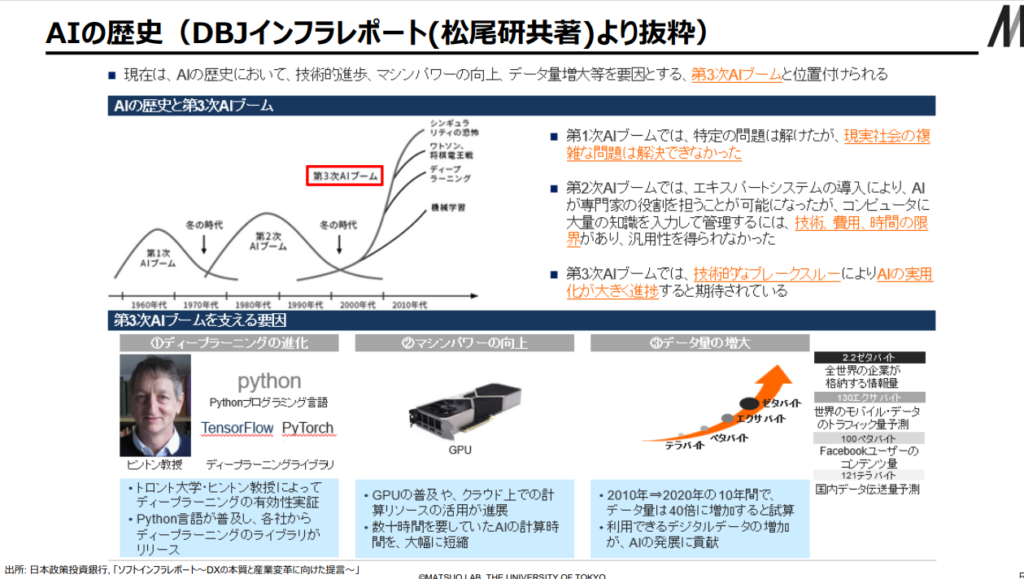
出典:AIの進化と日本の戦略 松尾研究室(23/2/17)

出典:日本マイクロソフト:「ChatGPT:OpenAIとMicrosoft」より 今話題の AI「ChatGPT」それを生んだ OpenAI と Microsoft
◆第1次AIブーム
概ね1950年代頃から機械学習は研究され始め、1953年のダートマス会議で人工知能の概念が提起されており、共時的に生体模倣のニューラルネットワークの概念も生まれた。
ニューラルネットワークは、人間の脳細胞と神経回路を模した演算によって、人間の行う複雑なパターン認識等を実現しようという試みであり、手書き文字認識で代表されるように『パターン分類を学習させよう』とした。
ニューラルネットワークの研究は、まず神経素子=ニューロンをモデル化する事から始まり、生理的研究から
①ニューロンは他のニューロンから電気的・化学的刺激を受けとる。
②受け取る刺激の総和が一定量を超えると『発火』して、他のニューロンに刺激を与える。
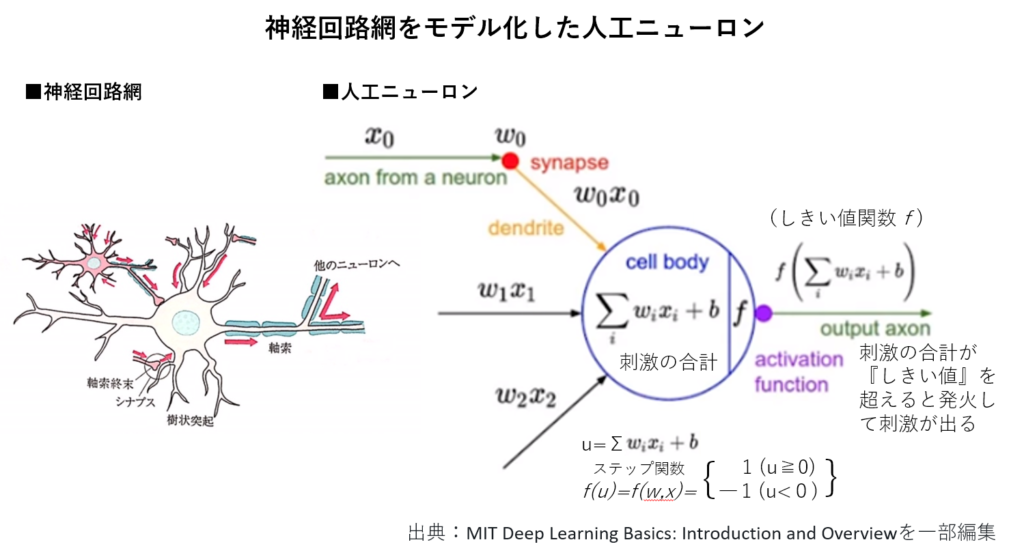
1958年、ローゼンブラットによりパーセプトロン(=3層ニューラルネットワーク)が開発され、第1次AIブームが始まった。
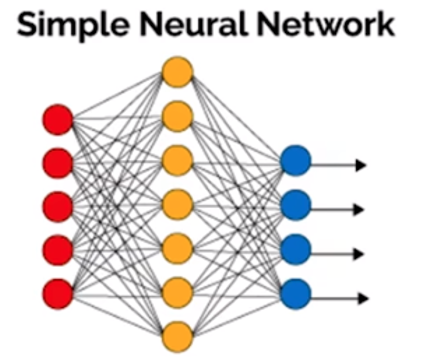
赤●:入力層 黄●:中間層 青●:出力層
❖第1次AIブームの下火(=冬の時代を迎える)
1969年、パーセプトロン学習とその限界を指摘したミンスキーらによってブームは下火になり、冬の時代に入った。
ミンスキーらは、入力層、中間層、出力層の3層パーセプトロンでは排他的論理和(XOR)演算で分類が直線で分離出来ない事を示した。
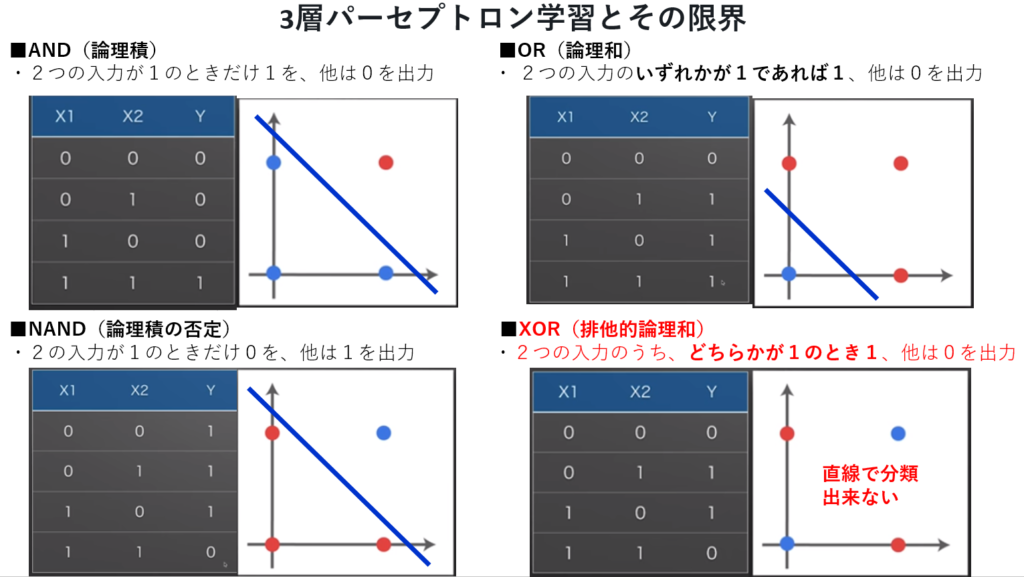
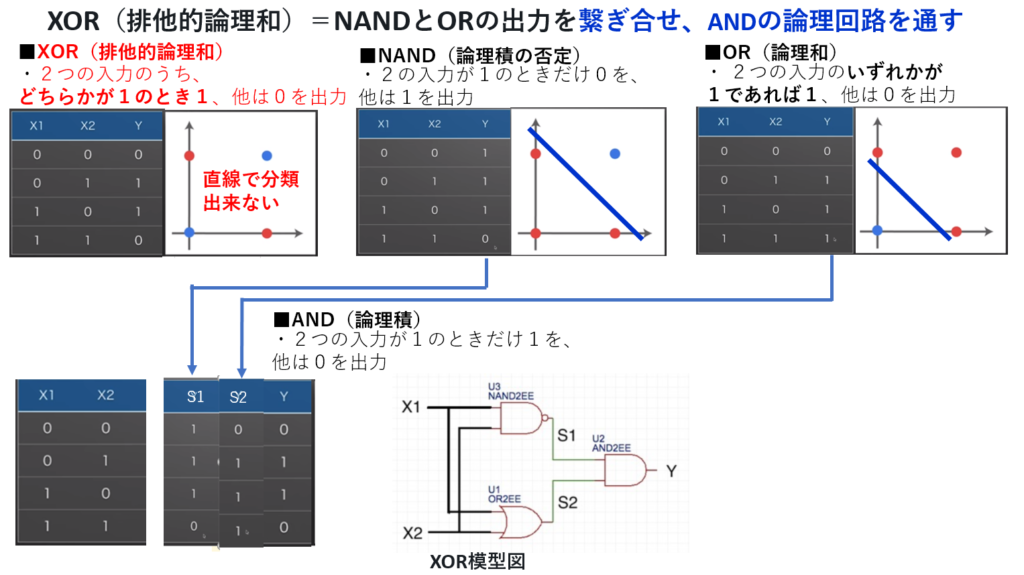
尚、 排他的論理和(XOR)演算はパーセプトロンを多層化する事で解決された。
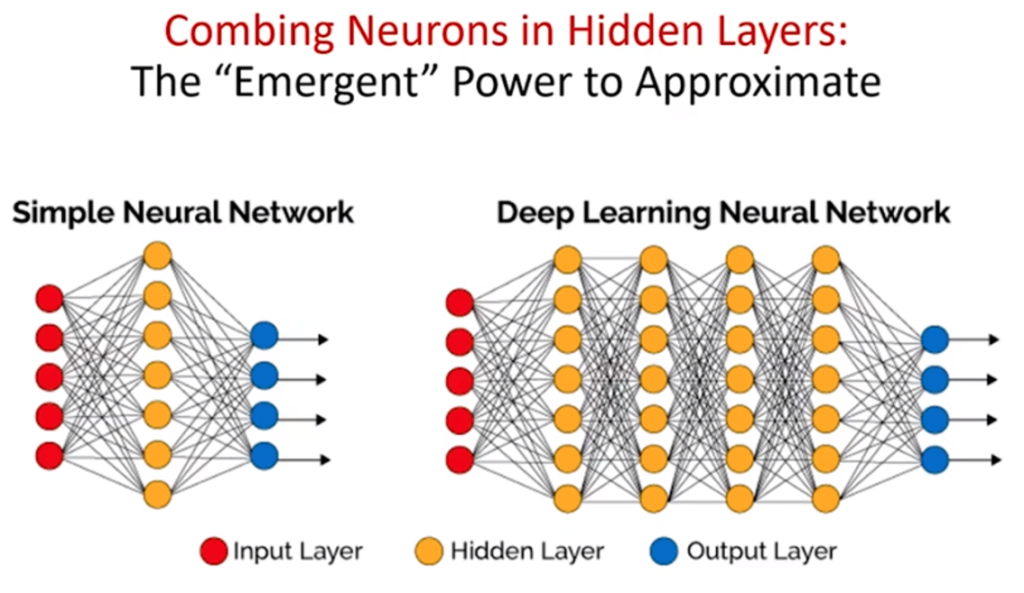
◆第2次AIブーム
1986年に隠れ層(多層パーセプトロン)を持つニューラルネットワークを高速に学習する『誤差逆伝播法』( バラバラに分布したデータを学習し法則性が発見できると実証)が発見され、第2次AIブームが起きた。
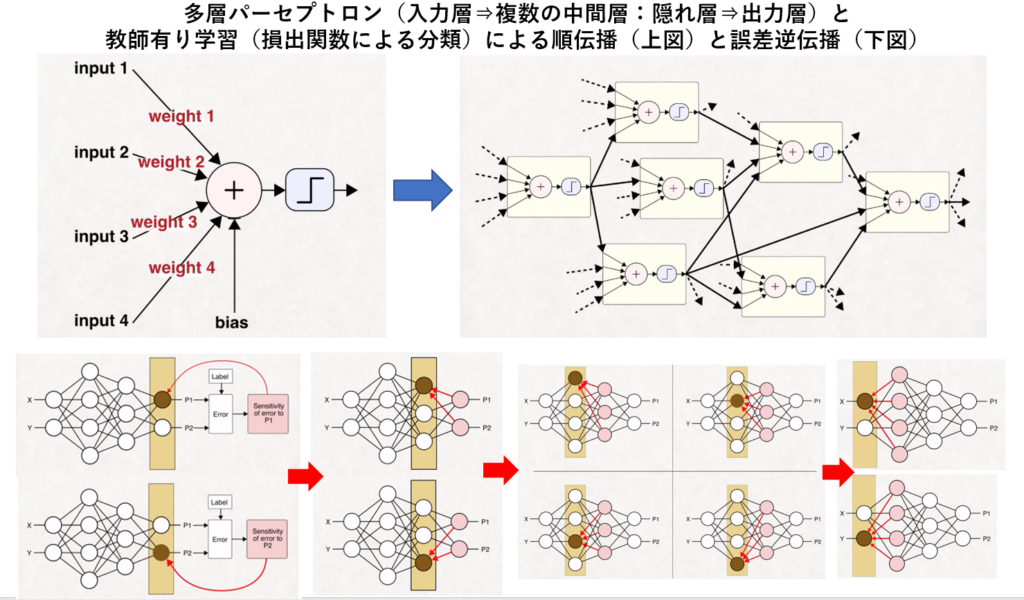
https://www.youtube.com/watch?v=r0Ogt-q956I
『バラバラに分布したデータ』から想起されるのは、中心極限定理を採用したブラック・ショールズ方程式である。当時、DECのプライベート展示会で隣のブースにて人工知能を活用した列車ダイヤ編成作成のデモを見た記憶が蘇り、ワークステーションが金融分野で使用されている事も同展示会で知り違和感を持ったが、今から振り返るとオプション計算等に活用されていたと理解でき、時代の『知』の一端を感じさせる動きであった。
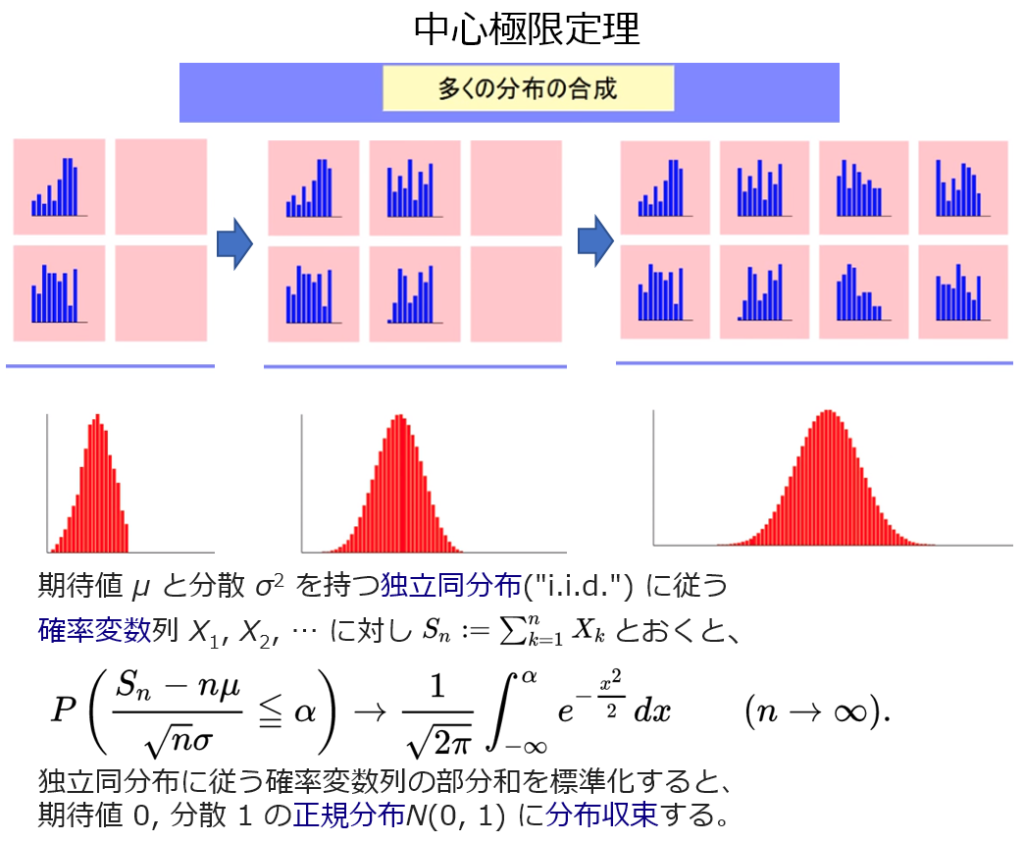
中心極限定理
❖第2次AIブームの下火(=冬の時代を迎える)
だが、AI学習に必要な大量のデータを準備するのが難しく、コンピュータの処理能力も低く、不満足な『精度』しか得られず、実用化に至ったAIは限られ、再度冬の時代を迎えた。
状況が変わり始めたのは、インターネットの普及により、2000年には『学習』に十分な大量データと、それを処理できる計算機(ゲーム機用で開発されたGUP)が比較的容易に手に入るようになってきた。
深い層を持つニューラルネットワークが既存手法を凌駕する精度を達成できるようになり、ディープラーニング(深層学習)という言葉が使い始めらるようになった。
◆第3次AIブーム
そして2012年に ジェフリー・ヒントン教授ら のグループによる CNN (Convoltutional Nueral Network:畳み込みニューラルネットワーク) で『精度』に関してブレークスルーが起き、第3次AIブームが始まった。

注: YOLOという接頭語は You Only Look Once
◆21世紀の時代を実感させるヒントン教授による新たな提案であるカプセルネットワーク(CapsNet)。
Hinton: “The pooling operation used in convolutional neural networks is a big mistake and the fact that it works so well is a disaster.”
大成功をおさめたCNNモデルに隠された問題点(プーリング:Max Pooling)を解決する為に自己否定し、新たな概念を導入した。
Max Poolingは元のデータから抽出された特徴量の最大値を取り、残りを切り捨てる。この操作により特徴同士の関係が分からないようになった。
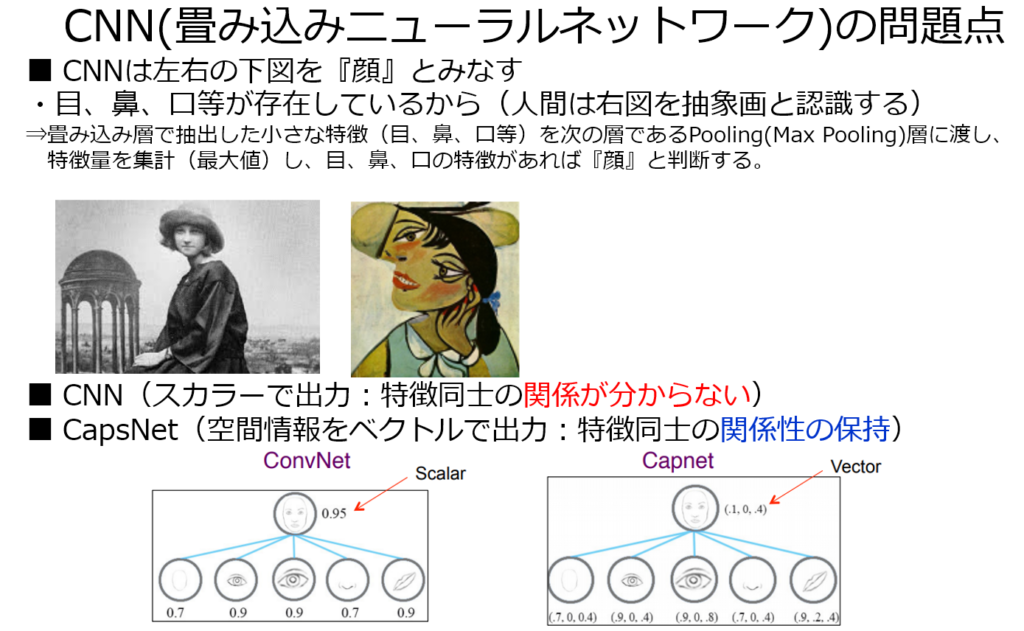
カプセルネットワークは個々の特徴を独立的に捉え、それぞれがどのような関係にあるかに注目する。この結果、特徴の位置関係が分かるようになり、人間の認識に近づき、AIの適用範囲が一気に広がる可能性を秘めている。
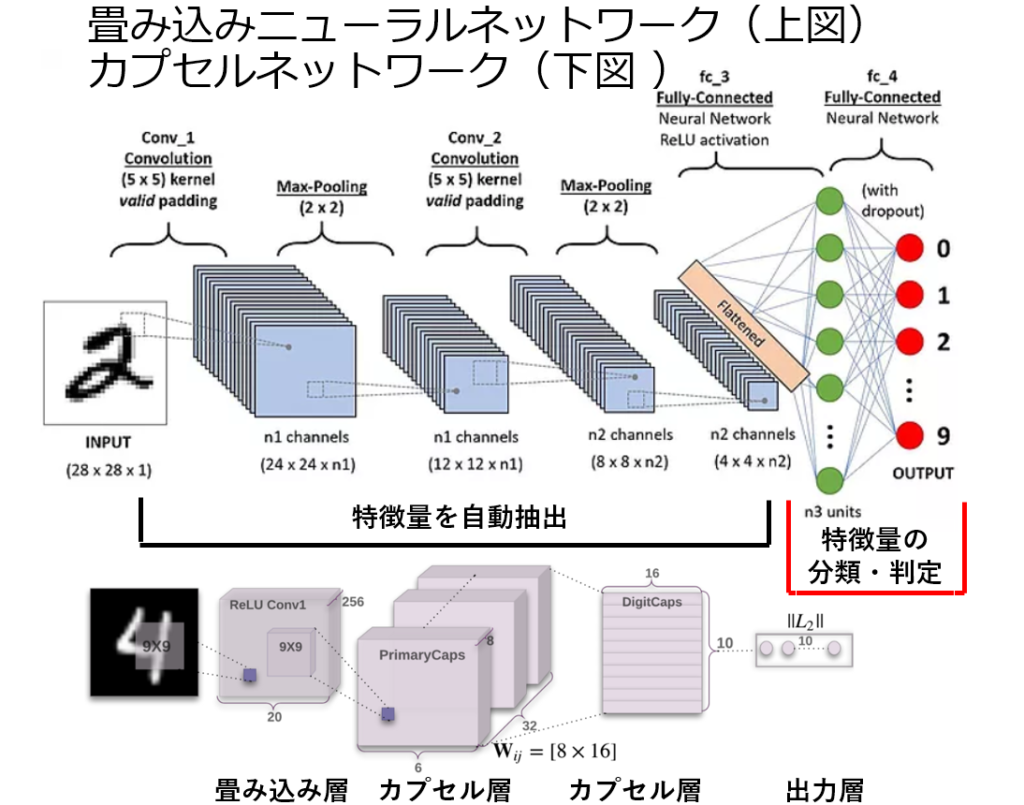
出典(下図); Dynamic Routing Between Capsules
http://papers.nips.cc/paper/6975-dynamic-routing-between-capsules.pdf
これと対照的なのが、金融工学の金字塔であるブラック・ショールズ方程式は、1987年のブラックマンディ危機で崩壊(暴落の過程で理論が破綻)した。この方程式が前提にしている確率計算(価格変動は正規分布する)に対して 鋭く問題点 (綿花の価格暴落や洪水の発生頻度から分散は『一定』ではなく大きく外れた動きの頻度は高い=べき乗分布)を指摘したマンデルブロ氏の批判を金融工学理論業界は無視し、同氏を業界から摘まみ出す事で ブ ラック・ショールズ方程式は、限定的な条件でしか機能しない現実を隠した。まさに “ the fact that it works so well is a disaster.”
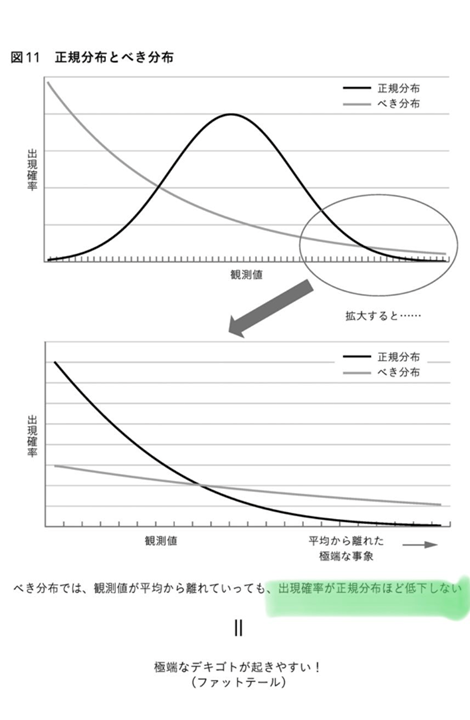
難解な数学理論(フーリエ変換も含む)で化粧を施し、リスク回避とは裏腹にレバレッジ金融を加速させ、尽きない利益を求める金融界と二人三脚でリーマンショックを引き起こし、挙句の果てに金融界の背骨をボキと折り、尻ぬぐいは各国の中央銀行からの巨額の金融緩和で逃げ、隠された問題点を自己否定するどころか、ほとぼりが冷めたら欠陥理論を使い同じ事を繰り返す金融業界には全く反省は無い。
具体的には『貸し手はいけない住宅購入者向け』サブ・プライムローンの再現と指摘されている 『貸し手はいけない企業向け』の CLO(Collateralized Loan Obligationの略 ) 。
昨年12月に元FRB議長であったイエレン氏がCLOの問題点を提起し、日銀と金融庁が日本の銀行にCLO保有額の調査を実施した。
■深層学習の更なる理解へのアプローチ
カプセルネットワーク (CapsNet) の概要理解からCNN (Convoltutional Nueral Network:畳み込みニューラルネットワーク) の特徴と隠された問題点が明確に理解できると考える。更にCNNの理解からDNN (Deep Nueral Network) の特徴と問題点も意識できると考えるが、ニュラールネットワークの原点であるパーセプトロンと誤差逆伝播法を基本構造とするDNNから理解を進める。
各ネットワークの理解については新たなメニューを用意し内容理解を深める。
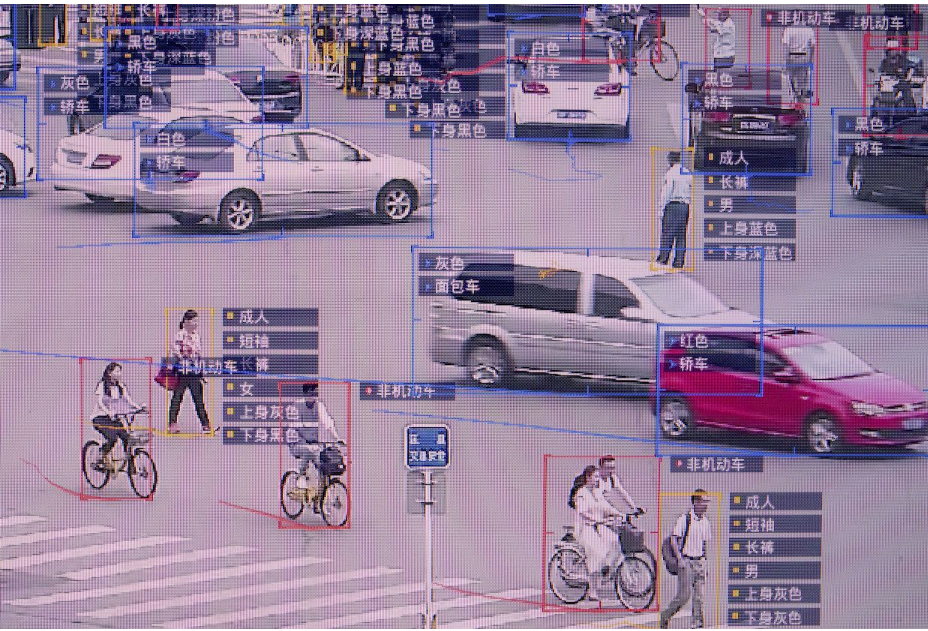
一方、第3次ブームの火付け役になったCNNの技術が支える『リアルタイム顔認証』は、民主主義的な社会を脅かすツールにも容易になりえる。
特に民主化運動の激化から香港政府が打ち出した覆面禁止( 緊急状況規則条例)=『リアルタイム顔認証』への重い問いかけに触れざるを得ない。
公的機関が『リアルタイム顔認証』ソフトを利用すれば、『完全でない』個人認証の誤りから、権力の誤った執行や投獄につがるリスクが有る。又該当者に対して同ソフトの利用承諾を得ずに利用した場合、個人情報保護法に違反する。
『リアルタイム顔認証』+運転免許証+パスポートと紐づけられ、データベースに情報が蓄積されれば最新の個人の日々の行動まで履歴が残る。
上記の文脈でMax Pooling の問題点を解決すべくカプセルネットワークで実現しようとする個々の特徴とその関係性に整合が取れるようになると、認識精度は高まり、その出力情報をデータベース上で蓄積されれば超監視社会を望む権力側にとって美味しい成果にも成り得る。
技術の進化を止める事は出来ず、技術を利用する社会は運用に対して『個人の権利』を保証し、権利侵害を起こさずを社会合意として臨まなければならない。
金融工学理論業界とセットで金融業界が犯したリーマンショックと同様の大災害(超監視社会の加速)を引き起こす事になる。
既にサンフランシスコ市、カリフォルニア州オークランド市等では『リアルタイム顔認証』ソフトの利用を禁止し、捜査機関が同ソフトを利用した捜査活動を禁じている。
fact that it works so well is a disaster.

◆第4次AIブーム
・Chat GPT-4の衝撃(=生成AIの衝撃)
⇒大規模言語モデル(=LLM:自然言語処理技術の進化)
⇒生成AIの進展は従来のディープラーニング技術の進展とは一線を課し、
⇒『誰もが』Chat GPT-4を使い、時代が大きく変わったと実感している。

上図の出典:AIの進化と日本の戦略 松尾研究室(23/2/17)
■■AIの安全性について研究する非営利の研究組織Future of Life Institute(FLI)の声明■■
■『GPT-4よりも強力なAIシステムの開発と運用を少なくとも6カ月間停止するように』呼びかける書簡を2023年3月28日に公開。
・現在1,000人以上が署名している。
⇒イーロン・マスク氏や、米Appleの共同創業者、スティーブ・ウォズニアック氏の名前もある。
・GPT-4のような言語モデルは
⇒ますます多様な分野のタスクにおいて、すでに人間に匹敵する働きができるようになっている。
⇒仕事の自動化だけでなく、偽情報の拡散にも利用される可能性があると警告している。
⇒またAIシステムが人間に取って代わり、文明をつくり変えるかもしれないという、遠い未来の可能性も提起している(ターミネーターの世界を彷彿)。
・制御不能なAI
⇒開発者でさえ「理解、予測、確実な制御」ができないほど高度なAI技術を開発しようと競っている。
◆6カ月の休止期間
・開発者に対して
⇒政策立案者と協力してAIガバナンスシステムを構築するように求めている。
・人が作ったコンテンツとAIが作ったコンテンツを区別するため
⇒AI「電子透かしシステム」の必要性を強調している。
・一時停止は
⇒AI開発の完全停止ではなく、
⇒先端技術をめぐる「危険な競争」から一歩後退することだと述べている。
◆書簡の背景
・開発スピードへの危機感
⇒進歩のスピードがあまりにも速いことから、
⇒GhatGPTはAI業界や一般市民がその利点と悪用の可能性についてほとんど検討する間もなく、
⇒GPT-4によってアップグレードされてしまった。
・GPT-4の著しく向上した能力は
⇒人々をさらにうろたえさせた。